I wrote a few pre-thoughts on the new Twitter API last August, but I’ve only just now got around to migrating my numerous apps.
First to escape the cull so far is Twitblock. I was initially pleased to see that it wasn’t denied access to all its old functions – blocking, reporting spam etc.. But what I found is now a huge problem is the new rate limiting model.
New Twitter rate limits mean re-engineering, not just migrating
The important change is that every endpoint (read: every specific API function) now has its own pool of requests available to your app. With only two tariffs and a varying amount of data available across methods, there is quite some disparity between the generous endpoints and the ones that are going to cripple your application.
Rather than simply migrating to some new API methods, the new rate limiting may mean a huge engineering job to work around new restrictions. Case and point: Let’s take a quick look at a pretty common function that you may wish to do – listing followers –
Paging though followers with Twitter API 1.1
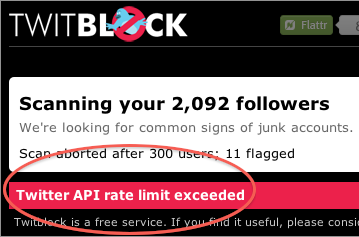
Twitblock retrieves the user entities from each ‘page’ of your followers in order to scan them. Even with the scanning deliberately slowed down, the old global limit of 350 requests per hour meant that I could grab the first few thousand of your followers while you sat and watched.
Using the old method I can now only get 15 pages of followers every 15 minutes. With a ridiculously low maximum of 20 per page this means I can only pull the first 300 of your followers before you’re sat looking at an error for the next 14 minutes or so.
So, late at night I bashed together the quickest solution I could to try and extend this experience. It involves grabbing just follower ids and resolving them to full user objects separately.
Get lists of IDs – not objects
Paging through just the user IDs of followers has the same rate limit, but you can get up to 5,000 at a time. Then all you have to do is resolve them to user objects yourself. The bulk user lookup method is more generous. The rate limit is 180 every 15 minutes and you can get 100 at once.
Using this method 100 per page, I can render 1,500 followers before the rate limit is hit. I could [and will] go further by caching larger batches of follower IDs in advance. (bigger re-engineering job).
You could also cache every Twitter user your system comes across, but given an arbitrary batch of 100 user ids, you’re probably still going to need to do an API lookup for at least one you don’t have. – Solution: Cache the whole of Twitter.
You’re doing it wrong
Twitter’s answer to any complaints about rate limits is going to be along the lines of “be cleverer“. Fair enough – to a degree – but there’s a lot of not-very-clever but fully functioning apps out there that are going to stop working very soon. If my apps are anything to go by, most of them are probably unfunded free software and a lot of authors are going to just let them die rather than stay up all night.
@Richy following our conversations, I built http://twproxy.eu/
There are quite a few security holes to plug, but it works
@richy It’s a great idea. I expect they’d have to be a paying partner though, like Datasift. Otherwise I suppose they could be seen as using the API to offer a competing service. i.e. breaking Twitter terms of use.
I wonder how long it’ll take for somebody to build a “Twitter Proxy” – apps use that for things such as user lists, username lookups and it caches the info. If a request comes in for something it hasn’t cached, it uses the “source Apps” API key, but caches the results for all.